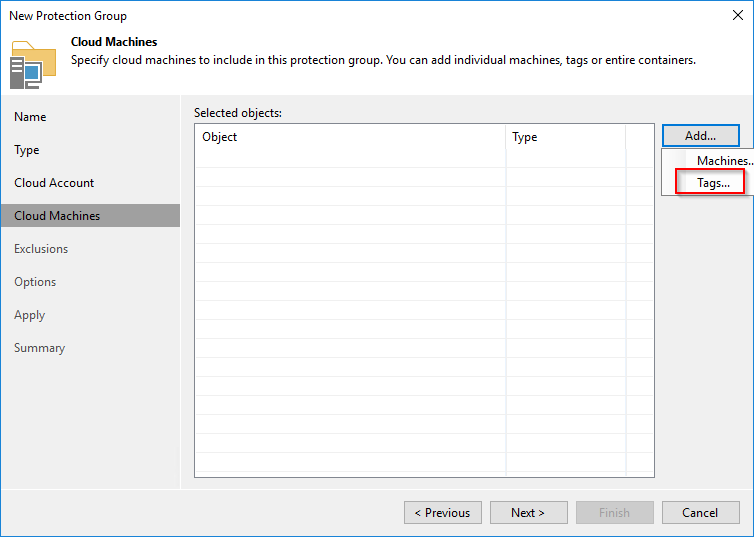
Security Information and Event Management (SIEM) systems provide comprehensive security monitoring, threat detection, and incident response capabilities. The main features a SIEM should provide are:
- Data Collection from a wide range of sources, including log files, network traffic, system events and security alerts.
- Normalization and Correlation where collected data is standardized, stored and events are correlated.
- Threat Detection and Analysis using predefined rules, statistical analysis, machine learning algorithms, and threat intelligence feeds.
- Alerting and Reporting to notify security personnel in real-time
- Incident Response and Forensics tools for investigating security incidents, conducting forensic analysis
All of the above make SIEM complex systems and also not cheap. However this does not minimize the importance of having SIEM deployed in your enterprise environment as a proactive line of defense against attacks that can compromise services availability and integrity.
Data protection solutions play another crucial role in making sure your environment is safe and can recover in case of any incident ranging from unintentional deletion to a sophisticated malware attack. It makes sense to integrate your backup infrastructure into your SIEM. Veeam offers the possibility to send events and alerts to a SIEM solution using syslog protocol.
Install Graylog
Let's look at first at the SIEM solution. For our lab environment, we chose Graylog Open as it offers a basic and free SIEM solution that can run on top of Ubuntu. We are using an Ubuntu 22.04 template with a static IP address that is resolvable via DNS. To install Graylog Open we have followed the instructions from this link. Please note that MongoDB and OpenSearch (or ElastichSearch) are required on the Graylog server. We will not repeat the steps since it does not make any sense to duplicate the content.
Configure Graylog for Veeam data ingestion
Once Graylog is installed, login to the admin interface using the http_bind_address configured in /etc/graylog/server/server.conf. For our lab it would be http://graylog_ip_address:9000, for example.
Go to System > Inputs. Select Syslog TCP and press Launch New Input


When the input is running, Graylog is ready to receive messages from Veeam infrastructure.
Configure Veeam Backup & Replication syslog integration
First, open the VBR console and go to Main menu > Options

In the new window got to Event Forwarding and under Syslog servers press Add. Configure the Graylog input: IP address or FQDN, port and protocol, Please note that only one syslog server can be configured

Press OK to save the syslog configuration and save it to VBR. You are now ready to test. The simplest way is to enable/disable Malware Detection configuration in VBR console. On main menu, press Malware Detection and in the new window make a change to your current configuration, for example deselect Enable file system activity analyses. Press OK in VBR console. Go back to Graylog console > Search and you will see an new event created. The event is generated by Veeam_MP application and the message description contains information about the VBR console event "Malware detection settings have been changed"

Configure Veeam ONE syslog integration
If you have Veeam ONE in your deployed, you can also configure it to send messages to Graylog. Open Veeam ONE client and from the main menu go to Settings > Server Settings (or just press CTRL+S)

Go to Syslog, and press Enable Syslog. Then add the syslog server FQDN or IP address, leave the syslog facility as mail, select the transport protocol and port (we are using TCP 1514).

Then select the syslog audit events that you want to send:
- Access to data
- Changes to data
- Privileged activities
- Login sessions
To test the connections settings, click Test Syslog Integration. Press OK to save the settings. Back in Graylog console you will see the test message:

Additionally you can select to send syslog messages whenever a Veeam ONE alert is triggered. Go to Alarm Management and in the filter field type "malware". You will be presented with the list malware related alarms available out of the box in Veeam ONE:

Let's change the settings for a couple of alarms. Select: "Veeam malware detection exclusion change tracking", right click on it and press Edit. In Alarm Settings window go to Notifications tab. From the Action drop down list select Send Syslog message and leave the Condition as Any state. This will enable sending syslog messages regardless of the alarm state: error, warning or resolved

Press OK to save. Repeat the steps from above for "Veeam malware detection change tracking" alarm. To trigger a malware configuration change alarm in Veeam ONE we need to change something in VBR console. So back to VBR console, from main menu press Malware Detection and change your current configuration. Remember to press OK to save the change. The change will trigger an alert in Veeam ONE - open the alert to see more details:

Open Graylog console and notice that the Veeam ONE message was received:

In our example we have integrated only 2 components from the infrastructure, but it is easy to understand how SIEM systems are critical to good security posture in the company by allowing the integration of alerts and events from different components. A simple infrastructure configuration change in the backup server could be correlated with an out of hours login on a jump server, and some suspicious network traffic. Having SIEM in place could help detect all of these events, notify operations teams and assist them in mitigating the breach.